iTOLの使い方
系統樹編集ソフト iTOLの使い方まとめ
系統樹のFigureをかっこよく仕上げられるツール。ダウンロード・インストール不要でウェブブラウザ上で操作できます。
websiteはこちら
iTOLとは
2017.8.3 作成

これが普通の系統樹 ほとんどデコってないもの。


上の系統樹をGeneiousというソフトでメイクアップしたもの。
Geneiousは類似のソフトと比較すると格安で使い勝手の良い有料ソフトです。これがあれば、大体の配列解析はできます。いくつかの無料ソフトを行ったり来たり、formatを変換したりという無駄な手間を省くことができてオススメ!
iTOLを使うと、系統樹のリーフ(種名や遺伝子名のところ)や枝だけじゃなく、それらの付加的な情報を図に入れることができます。
sampleのデータセットを使うと、下のような感じになります!
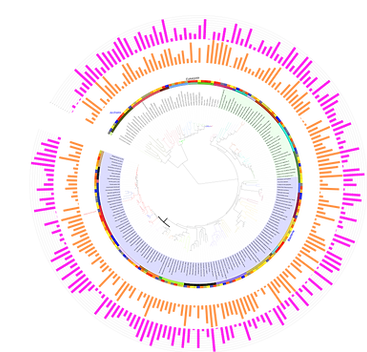

A
C
B

すげー!ってなるんだけど、厄介なのが、データセットを使って、いろいろメイクアップをするんだけど、そのデータセットがtext file (*.txt)で要求されていること。 infomatician なら屁でもないことだけど、wetの研究者にとってはちょっと敷居が高い。
そこで、このページではwetの研究者向け(エクセルが使える程度)の人に使い方をさらっと教えます。
必要なもの
iTOLを使って系統樹をメイクアップするのに最低限必要なものは、系統樹のnewickファイルです。
これは多分大体の系統樹作成ソフトなら *.newick で出力されていると思うので問題ないでしょう。
メイクアップの方法は2つあります。
1つは、系統樹を元にiTOL上でマウスを使って、ポチポチと編集していく方法です
この場合できる操作は、枝のトポロジーや太さ、全体の長さ、リーフの書式、そして枝の色とrangeの設定です。
rangeは、上の例でいうと、リーフにかぶさっている色のことです。
もう1つは、テキストファイルを使ってデータセットを追加する方法です。
各リーフに対応した値が入力されたテキストファイルをドラッグ&ドロップすることで、上の図のように、棒グラフやrangeをつけたり、リーフの後ろに▲や◯と言った記号をつけることができます。また、分岐点(ノード)を指定して、そこより外側の線の色やスタイルを変えることや、線上の任意のところに
▲や◯の記号を載せることも可能です。
ということで必要なものは・・・
my_tree.newick (系統樹)
dataset_scalebar.txt
dataset_range.txt
dataset_symbol.txt
and_so_on.txt
と言った具合で系統樹とテキストファイルだけで十分です。
と言っても具体例を見ないとわかりにくいと思います。
iTOLではサンプルが豊富に揃っており、サンプルデータでガチャガチャ遊んでるだけで、なんとなくやりたいことができるようになると思います。
使い方:サンプルデータで遊ぶ
まずはアカウントを作ります。
そして自分のアカウントにログインしてください。
サンプルデータのダウンロード
HELPページを見てください。
とても親切に書いてあるので英語が得意ならもうこの先は見ずにiTOLのサイトだけで十分理解できます。
Annotating Treesの項目の下の方にあるexample_data.zipをクリックしてサンプルデータを一括でダウンロードします。
上のタブからMy Treesのページに移動し、ダウンロードしたtree_of_life.tree.txtをアップロードする。

上の図が出てきたと思います。
普通の平行線で書かれた系統樹の場合は、右上のCotrolボックスのBasicタブの一番上にあるDisplay modeからcircularを選んでください。
このままではリーフが数字で表されており、何がなんなのかさっぱりです。
続いて、先ほどダウンロードしたフォルダの中にlabels.txtがあると思います。
labels.txtをこのページにドラッグ&ドロップしてください。
すると、数字だったリーフ名が種名になりました。
また、range.txtもドラッグ&ドロップして見ましょう。
見栄えを良くするためにcontrol ボックスのLabel でAlignを選びましょう。
あっという間にちょっとかっこいい系統樹になりました。
このようにテキストファイルさえあれば、簡単に系統樹をドレスアップできます。
あとはサンプルデータを適当にドラッグ&ドロップして遊んで見ましょう。
上の系統樹の図Aは
color_strip.txt
tol_heatmap1.txt
simple_bar.txt
simple_bar2.txt
を追加し、色を適当に変えました。
txtファイルの状態で色を指定できますが、これはブラウザ上で後で変更できます。
txtでの色の指定は#aa00ffといった{シャープ+6桁の文字}で指定するか、rgba(213,120,100,0.6)といったRGBa(三原色+透明度)で指定できます。
しかし、ほとんどの人はブラウザ上で指定した方が簡単でしょう。
好きな色を見つけたら、それのコードだけは覚えて、使い回せばいいと思います。
参考までにcolor hex color codesというサイトで色とそのコードの対応を教えてくれます。
使い方2:text fileの中身
テキストファイルの作り方が一番のハードルです。
exampleやtemplateを見ながら作成したらは迷うこともないでしょう。
templateのは、HELP -> Annotating Treesの3段落目にあるZip fileをクリックするとダウンロードできます。
あとは自分のデータに合わせて、テキストを書き換えるだけです。
プログラミングをちょっとでもかじっていればこれ以上説明はないです。
それではどうぞiTOLを楽しんでください。
蛇足として、プログラミングをしたことのない人向けに、テキストファイルの中身を簡単に説明します。
ダウンロードしたZip fileの中になるdataset_symbols_template.txtを例に見て見ましょう。
Macならテキストエディタ、WindowsならWordでひらけます。
テンプレートなのにめっちゃ文字が多くてげんなりするかもしれませんが、実際に必要な部分はこの1割もなく、ほとんどが丁寧な説明ですので安心してください。
DATASET_SYMBOL
#Symbol datasets allow the display of various symbols on the branches of the tree. For each node, one or more symbols can be defined.
#Each symbol's color, size and position along the branch can be specified.
#lines starting with a hash are comments and ignored during parsing
#=================================================================#
# MANDATORY SETTINGS #
#=================================================================#
#select the separator which is used to delimit the data below (TAB,SPACE or COMMA).This separator must be used throughout this file (except in the SEPARATOR line, which uses space).
#SEPARATOR TAB
#SEPARATOR SPACE
SEPARATOR COMMA
#label is used in the legend table (can be changed later)
DATASET_LABEL,example symbols
#dataset color (can be changed later)
COLOR,#ffff00
#=================================================================#
# OPTIONAL SETTINGS #
#=================================================================#
#each dataset can have a legend, which is defined below
#for each row in the legend, there should be one shape, color and label
#shape should be a number between 1 and 5:
#1: square
#2: circle
#3: star
#4: right pointing triangle
#5: left pointing triangle
#LEGEND_TITLE,Dataset legend
#LEGEND_SHAPES,1,2,3
#LEGEND_COLORS,#ff0000,#00ff00,#0000ff
#LEGEND_LABELS,value1,value2,value3
#=================================================================#
# all other optional settings can be set or changed later #
# in the web interface (under 'Datasets' tab) #
#=================================================================#
#largest symbol will be displayed with this size, others will be proportionally smaller.
MAXIMUM_SIZE,50
#Internal tree nodes can be specified using IDs directly, or using the 'last common ancestor' method described in iTOL help pages
#=================================================================#
# Actual data follows after the "DATA" keyword #
#=================================================================#
#the following fields are required for each node:
#ID,symbol,size,color,fill,position,label
#symbol should be a number between 1 and 5:
#1: rectangle
#2: circle
#3: star
#4: right pointing triangle
#5: left pointing triangle
#size can be any number. Maximum size in the dataset will be displayed using MAXIMUM_SIZE, while others will be proportionally smaller
#color can be in hexadecimal, RGB or RGBA notation. If RGB or RGBA are used, dataset SEPARATOR cannot be comma.
#fill can be 1 or 0. If set to 0, only the outline of the symbol will be displayed.
#position is a number between 0 and 1 and defines the position of the symbol on the branch (for example, position 0 is exactly at the start of node branch, position 0.5 is in the middle, and position 1 is at the end)
DATA
#Examples
#internal node will have a red filled circle in the middle of the branch
#9606|184922,2,10,#ff0000,1,0.5
#node 100379 will have a blue star outline at the start of the branch, half the size of the circle defined above (size is 5 compared to 10 above)
#100379,3,5,#0000ff,0,0
#node 100379 will also have a filled green rectangle in the middle of the branch, same size as the circle defined above (size is 10)
#100379,1,10,#00ff00,1,0.5
1行目でデータセットの定義
「#」で始まる行はコメント行と言い、プログラムには読み込まれない文章。いわゆるメモ欄
データの情報を何で区切るかの指定
#をつけたり消したりして変えられるようにしてくれている
データセットの表示方法(ここではどんなシンボルマークを使うか)などの情報が書かれており、下のAcutual dataのオプションになる。
ID, Symbol, size,...の順に指定する。
ここに書かれている数値や値を自分の系統樹とデータに応じて書き変える。
リーフの名前を2つ入れることで、その間のノード(分岐)を指定できる。
値と値の間は上で決めたセパレーターで区切る。このファイルではカンマを選んでいる。
わかりやすいように、Excelでこれらの情報を一括で指定した後にcsv形式で保存じ、ここにコピペすると効率的。
最後にこれを保存して、My Treesから自分の系統樹を開き、作成したテキストファイルをドラッグ&ドロップするだけです。
頑張ってください。